JiraCDflow
1. Overview
a) Process Introduction
Process Purpose
Automate the upgrade of SQL, configuration, and code using a workflow approach. Currently implemented for UAT environment automated upgrade process.
Main Logic
Testers enter upgrade data in the release management system. Clicking the publish button triggers image submission + triggers the jiracdflow program's /cicdflow/ API endpoint.
jiracdflow program /cicdflow/ API interaction logic with Jira The API receives request_data from the release system and triggers corresponding operations based on whether the email title field exists in the JSON data:
- When email does not exist: This is a first-time upgrade. A Jira ticket is created, and the Jira webhook triggers the jiracdflow program's /cicdflow/jira/ API to run the upgrade logic.
- When email exists: This is a UAT iterative upgrade. The Jira ticket data is updated, and the Jira webhook triggers the jiracdflow program's /cicdflow/jira/ API to run the upgrade logic.
- jiracdflow program /cicdflow/jira API upgrade logic
New field data is obtained from the JSON data submitted by the release system; old data is retrieved from the database saved during the last upgrade
When sql_info field data is not empty or differs from the last upgrade, the Jira ticket status enters
<Pending SQL Execution>. The sql_info data is submitted to the Archery backend for DBA review and execution (review and execution permissions can be separated; subsequent execution can be delegated to ops or testers). The Jira workflow triggers<Submit SQL>to enter<SQL Executing>status, waiting for SQL execution success to be manually confirmed via<SQL Execution Successful>to proceed to the next step.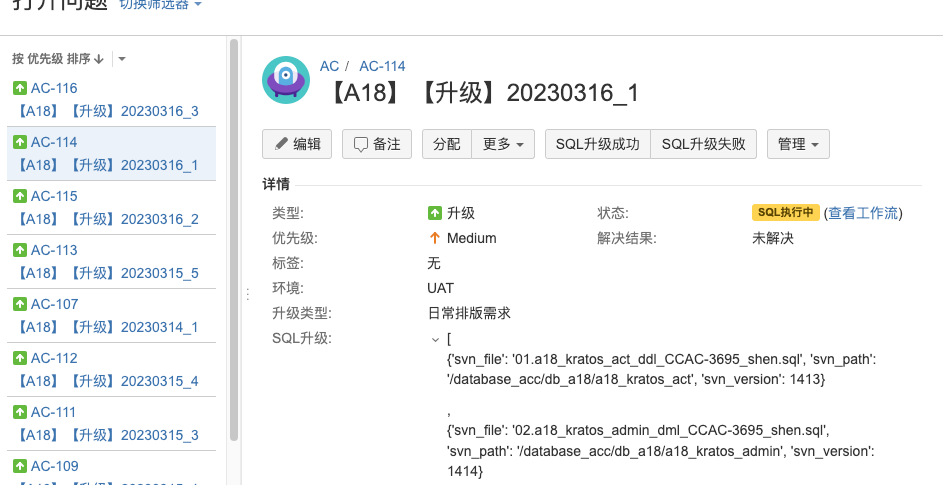
When apollo_info or config_info field data is not empty or differs from the last upgrade, the Jira workflow status enters
<CONFIG Executing>, waiting for manual configuration updates and then manually triggering<Config Upgrade Successful>to enter<CODE Executing>status.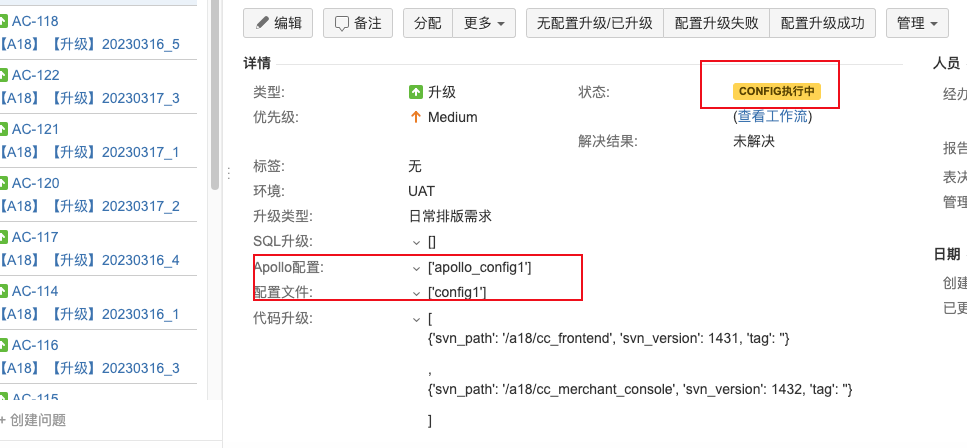
When code_info field data is not empty or differs from the last upgrade, the Jira workflow status enters
<CODE Executing>. The program calls cmdb_api to execute the code upgrade operation. Upon successful upgrade, it automatically triggers<Code Upgrade Successful>to enter<UAT Upgrade Complete>status.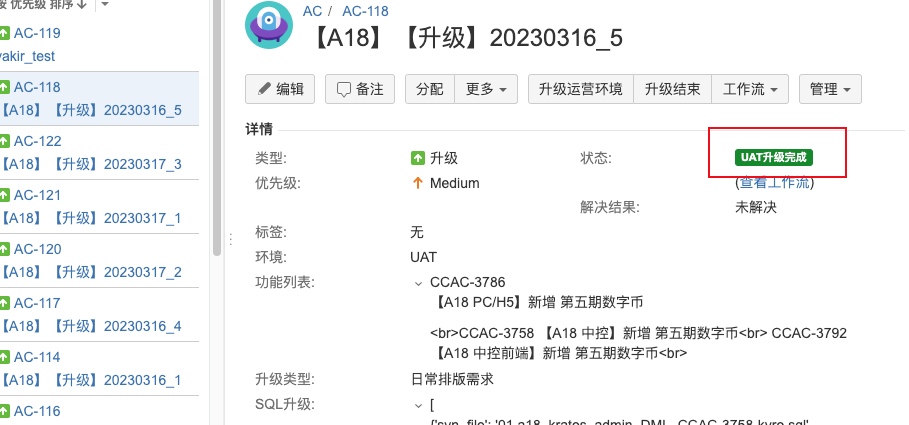
b) Prerequisites
Archery Backend Deployment Configuration Deployment host: 172.22.1.69 Deployment path: /opt/Archery-1.9.1/src/docker-compose
Jira Backend Deployment Configuration Deployment host: 172.30.2.51 Deployment path: /opt/py-project/jira-docker
jiracdflow Program Deployment Deployment host: 172.30.2.51 Deployment path: /opt/py-project/jiracdflow
2. Deployment and Configuration Guide
Application startup has no order dependency, but there are dependencies between their API calls
a) API Application: jiracdflow
Application Operations
# Start MySQL
mkdir -p /opt/docker_volume
docker run --name devops-mysql \
-e MYSQL_ROOT_PASSWORD=123qwe \
-e MYSQL_DATABASE=jiracdflow \
-v /opt/docker_volume/devops-mysql/data:/var/lib/mysql \
-v /opt/docker_volume/devops-mysql/log:/var/log/mysql \
-p 3306:3306 \
-d mysql --character-set-server=utf8mb4
# Configuration file adjustments
vim jiracdflow/settings/dev.py
vim uwsgi.ini
# Enter application home directory and activate Python virtual environment
cd /opt/py-project/jiracdflow
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt
# Start/restart application
uwsgi --ini uwsgi.ini
uwsgi --reload logs/uwsgi.pid
# Log information
tail -f logs/app.log # Application log output
tail -f logs/uwsgi.log # Console outputAPI Operations
/cicdflow/ 接口
# 源码位置:cicdflow/views.py 下 CICDFlowView 视图函数。
# POST 请求:接收自动发包系统 request data,符合升级数据格式触发升级操作。升级数据格式如下:
{
"project": "AC",
"summary": "Daily task xxx",
"issue_type": "升级",
"env": "UAT",
"upgrade_type": "日常排版需求",
"function_list": [],
"sql_info": [],
"config_info": ["config1"],
"apollo_info": ["apollo_config1"],
"code_info": [
{
"svn_path": "/a18/cc_frontend",
"svn_version": 1431,
"tag": ""
},
{
"svn_path": "/a18/cc_merchant_console",
"svn_version": 1432,
"tag": ""
}
]
}
/cicdflow/jira/ 接口
# 源码位置:cicdflow/views.py 下 JiraFlowView 视图函数
# POST 请求:接收 Jira 的 webhook 请求,根据 webhook 请求类型(新建事件:issue_created & 更新事件:issue_updated)与请求数据中的 status 字段执行不同操作。
issue_created 事件:Jira 工单首次创建,触发 `<SQL待执行>`
issue_updated 事件:Jira 工单被更新,触发 webhook 流程b)数据库审计平台:Archery
开源代码地址:https://github.com/hhyo/Archery 程序使用docker 启动,宿主机需要安装 docker、docker-compose
应用部署
# 进入应用目录,修改
cd /opt/Archery-1.9.1/src/docker-compose
# 修改 Archery 应用环境变量
vim .env
# 添加应用持久化存储目录
mkdir -p ./archery/sql_api/
mkdir -p ./archery/sql/ && cd ./archery/sql/
mkdir engines migrations templates
# 修改 docker-compose 配置
vim docker-compose.yml配置与流程
配置相关
实例管理-实例列表 添加 UAT 数据库实例,使用对应库与账号新增
系统管理-配置项管理-系统设置
# goinception 配置
配置 goinception 连接信息,用 docker 启动,在宿主机查看
# SQL 上线
AUTO_REVIEW_WRONG: 0 # 关闭自动审核驳回
MANNUAL: ON # 开启手动上线 SQL
# 其他配置
DEFAULT_RESOURCE_GROUP # 默认资源组
API_USER_WHITELIST: admin、cdflow # API 白名单用户
SIGN_UP_ENABLED: OFF # 关闭注册功能- 系统管理-配置项管理-工单审核流配置
# 工单审核流程配置
选择工单类型:SQL上线申请
选择资源组:A18 & A19
变更审批流程:默认只让 DBA 组进行审核系统管理-资源组管理 添加资源组:A18、A19
系统管理-其他配置管理-(用户管理|权限组管理) 添加用户:cdflow、DBA 用户 关联用户到权限组:DBA 组
流程相关
SQL 流程只需关注 SQL上线 功能的步骤 SQL上线 工单目前可以审核执行分离,DBA 审核,其他用户执行 DBA 执行工单时,通过唯一工单名称搜索所有待执行工单,按升级序号顺序执行
<等待审核人审核>状态:SQL 工单初始化提交,等待 DBA 审核。<审核通过>状态:DBA 审核通过,等待执行。<执行有异常>与<人工终止流程>状态:SQL 执行异常或人为终止流程,需要重新提交 SQL 工单。(如果同一升级中异常工单后有其他工单,其他工单暂不执行,等待新工单提交后按顺序继续执行)<已正常结束>状态:SQL 成功人工/自动执行,单个 SQL 正常执行结束。
调整源码显示前台数据
仅调试:docker exec -it archery /bin/bash 修改:使用外部持久化存储挂载覆盖文件的方式,见 docker-compose.yml 重启生效:docker restart archery
# 1)数据库新增字段:sql_index(升级序号)与 sql_release_info(SQL版本信息)
# SqlWorkflow models 类添加字段配置
vim sql/models.py # 242行前后
class SqlWorkflow(models.Model):
"""
存放各个SQL上线工单的基础内容
"""
sql_index = models.IntegerField("升级序号", default=0, blank=True, null=True)
sql_release_info = models.CharField("SQL版本信息", max_length=50, default=0, blank=True, null=True)
# 进入应用虚拟环境迁移更新数据库
source /opt/venv4archery/bin/activate
python manage.py makemigrations
python manage.py migrate
# 2)前端展示接口:/sqlworkflow/
# 新增 sql_index 与 sql_release_info 字段展示
vim sql/templates/sqlworkflow.html # 187行前后
columns: [
{
title: '升级序号',
field: 'sql_index'
}, {
title: 'SQL版本信息',
field: 'sql_release_info'
},
# 修改 workflow_name 字段展示
vim sql/templates/sqlworkflow.html # 194行前后
}, {
title: '工单名称',
field: 'workflow_name',
formatter: function (value, row, index) {
var span = document.createElement('span');
span.setAttribute('title', value);
if (value.length > 20) {
span.innerHTML = "<a href=\"/detail/" + row.id + "/\">" + value + "</a>";
} else {
span.innerHTML = "<a href=\"/detail/" + row.id + "/\">" + value + "</a>";
}
return span.outerHTML;
}
# 修改返回前端的数据(新增返回数据字段、修改返回排序规则)
vim sql/sql_workflow.py # 111行前后
workflow_list = workflow.order_by("workflow_name", F("sql_index"))[offset:limit].values(
"id",
"sql_index",
"sql_release_info",
# 3)api 与前端 提交新工单接口 /api/v1/workflow/
# 新增 WorkflowSerializer 序列化器sql_index 与 sql_release_info 数据(默认值用于前端手动提交时使用)
vim sql_api/serializers.py # 307行前后
class WorkflowSerializer(serializers.ModelSerializer):
sql_index = serializers.CharField(allow_blank=True, allow_null=True, default=0)
sql_release_info = serializers.CharField(allow_blank=True, allow_null=True, default='手动提交工单')
#Meta 类新增 sql_index 与 sql_release_info 的 required 值为 False
# 新增 WorkflowContentSerializer 序列化器获取 sql_index 与 sql_release_info 数据
vim sql_api/serializers.py # 347行前后
class WorkflowContentSerializer(serializers.ModelSerializer):
def create(self, validated_data):
"""使用原工单submit流程创建工单"""
sql_index = workflow_data.get("sql_index", 0)
sql_release_info = workflow_data.get("sql_release_info", "手动提交工单")
# 新增 WorkflowContentSerializer 序列化器添加数据时带上 sql_index 与 sql_release_info 字段
vim sql_api/serializers.py # 404行
workflow_data.update(
sql_index=sql_index,
sql_release_info=sql_release_info,c)工作流平台:Jira
应用部署配置
开源代码路径:https://github.com/lyy289065406/jira-docker 程序使用docker 启动,宿主机需要安装 docker、docker-compose
# 下载源码进入应用目录
# 源码是破解版 Jira,部署完成首次打开需要在源码 github 上获取注册码
cd /opt/
git clone https://github.com/lyy289065406/jira-docker && cd jira-docker
# 修改 docker-compose.yml 配置
vim docker-compose.yml
services:
mysql:
environment:
- MYSQL_ROOT_PASSWORD=xxxxx
- MYSQL_DATABASE=jira
- MYSQL_USER=jira
- MYSQL_PASSWORD=123qwe
jira:
environment:
# Jira JVM 启动内存
- JVM_MINIMUM_MEMORY=2g
- JVM_MAXIMUM_MEMORY=4g
ports:
- "8090:8080"
# 修改 jira tomcat 配置(解决 nginx 代理 http 访问异常问题)
vim ./jira/conf/server.xml # connector 标签中添加配置
<Connector port="8080"
proxyName="jira.example.com"
proxyPort="80"
/>
# 修改 jira 连接数据库配置(与 docker-compose.yml 配置一致)
vim ./jira/atlassian/dbconfig.xml
<jira-database-config>
<jdbc-datasource>
<url>jdbc:mysql://jira_db:3306/jira?useUnicode=true&characterEncoding=UTF8&sessionVariables=default_storage_engine=InnoDB</url>
<driver-class>com.mysql.jdbc.Driver</driver-class>
<username>jira</username>
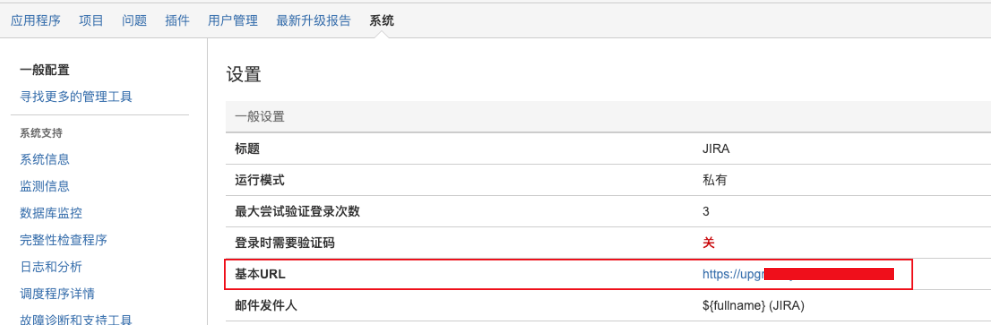
<password>123qwe</password>系统配置
- baseUrl:修改为与前台访问地址一致
- 添加电子邮件

- 添加 webhook:问题类型选择已新建与已更新,JQL 过滤工作流的事件 AC webhook:project = AC and issuetype in (升级) and status in (SQL待执行, SQL执行中, CONFIG执行中,CODE执行中,"开发/运维修改")
QC webhook:project = QC and issuetype in (升级) and status in (SQL待执行, SQL执行中, CONFIG执行中,CODE执行中,"开发/运维修改") 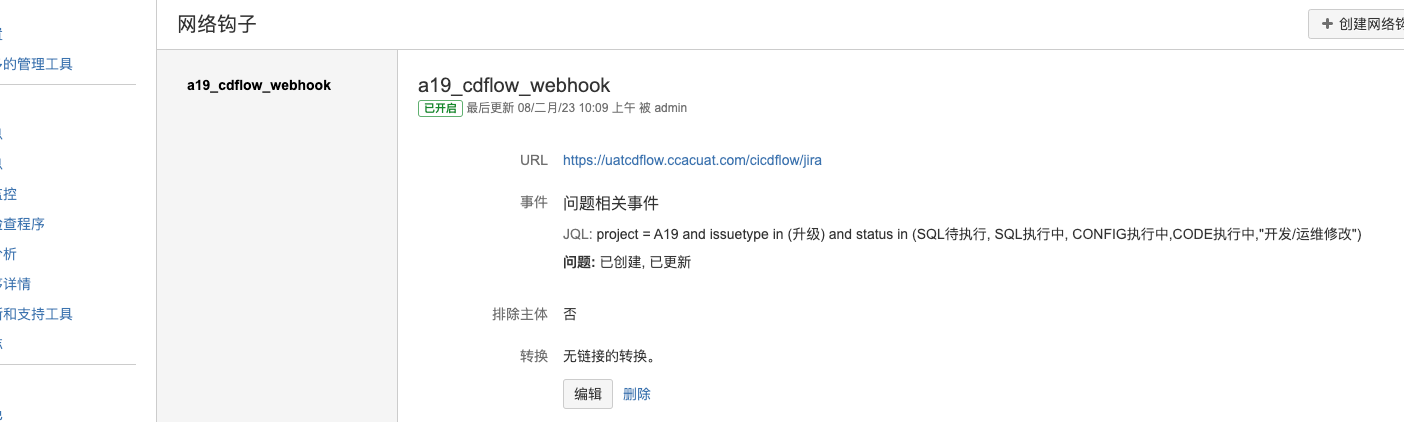
清理 webhook:delete from ao_4aeacd_webhook_dao;
问题配置
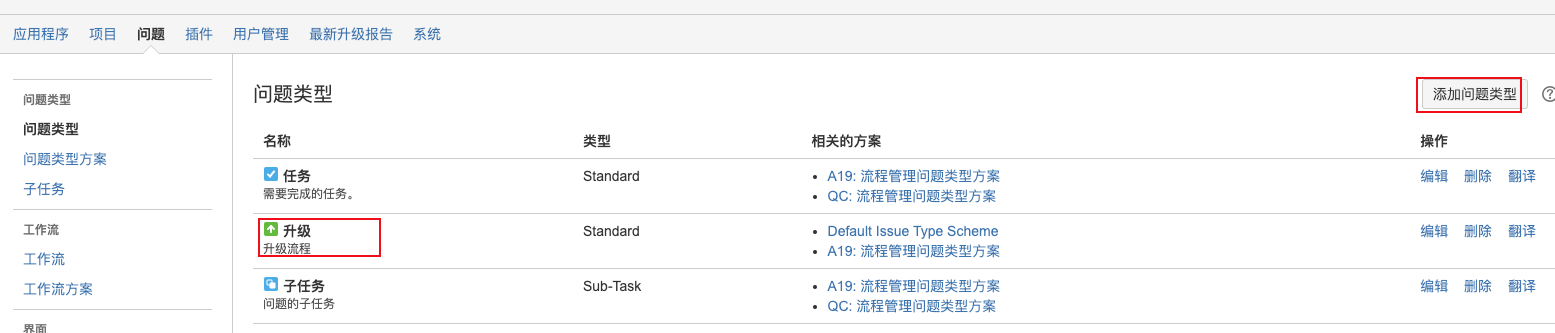
- 问题类型:新建升级类型,关联问题类型方案到项目。问题类型方案设置 升级 为默认问题
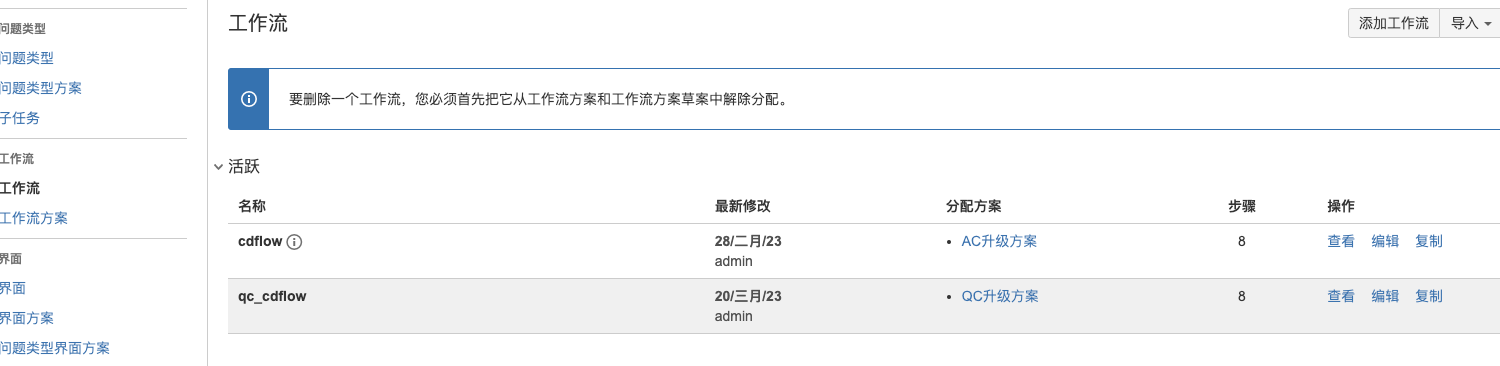
- 工作流:新建 cdflow 工作流,关联工作流方案到项目
- 界面:修改界面字段配置,关联界面方案到项目

- 字段 + 自定义字段:新增字段,将字段关联到问题类型、项目、界面
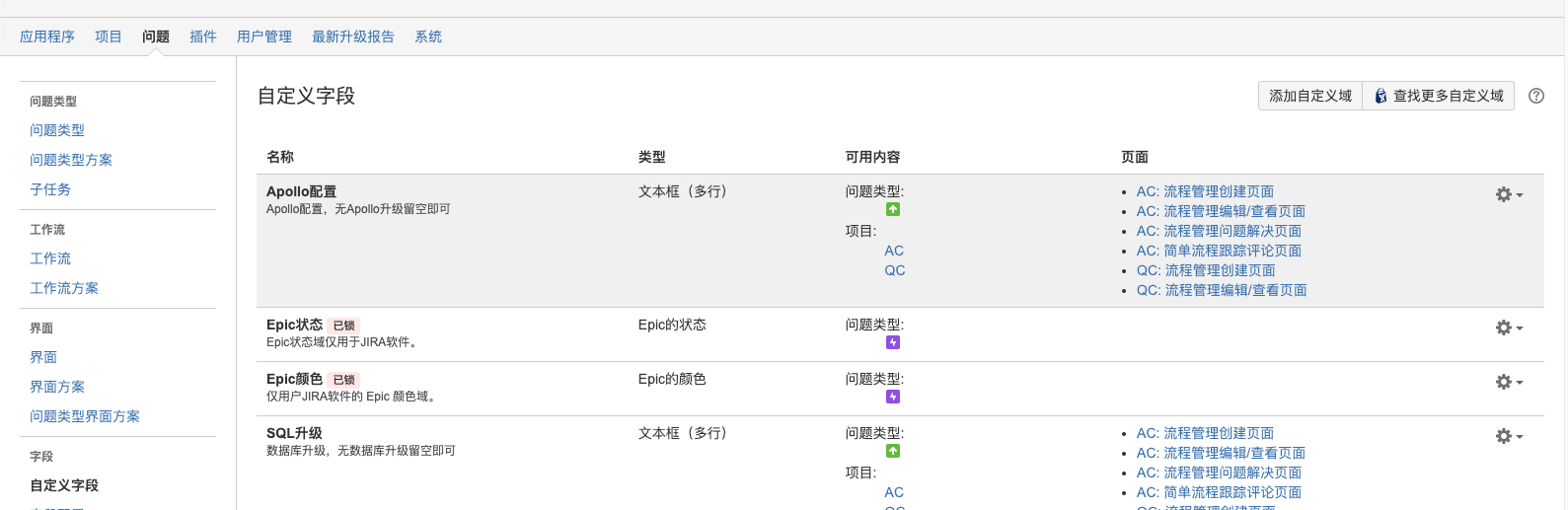 + 新增字段配置与字段配置方案,进行关联
+ 新增字段配置与字段配置方案,进行关联 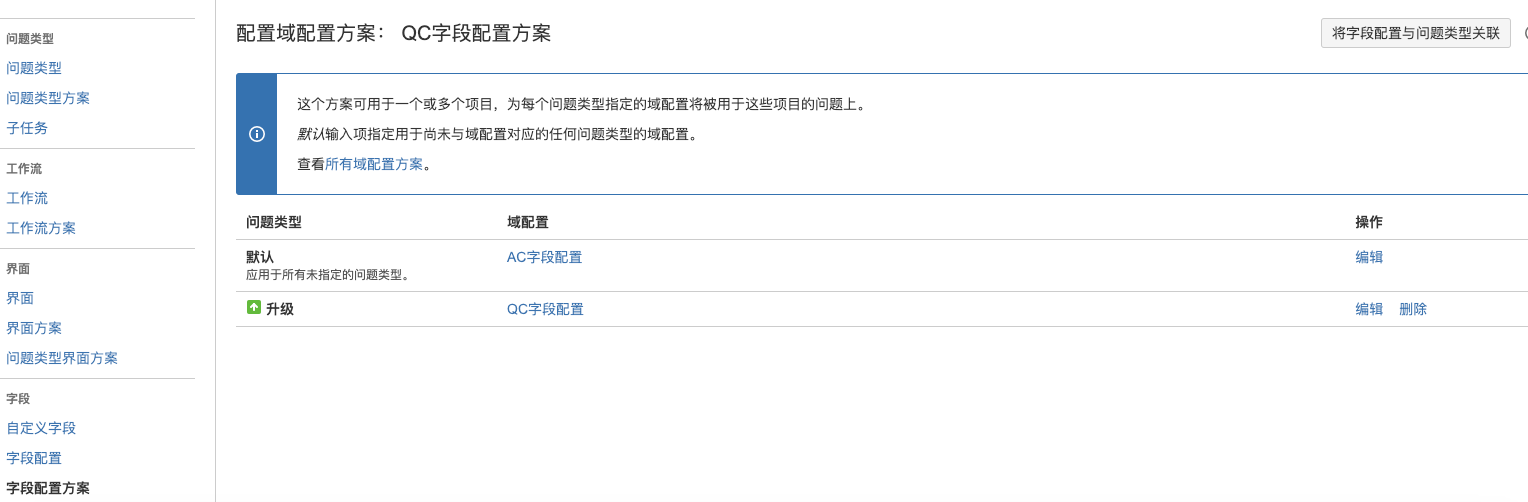
- 通知方案:新建通知方案,关联项目到通知方案中(通知方案通知组为新增 notice 组)

- 权限方案:新建权限方案,根据需求设置用户与组对项目操作的权限,关联权限方案到项目中
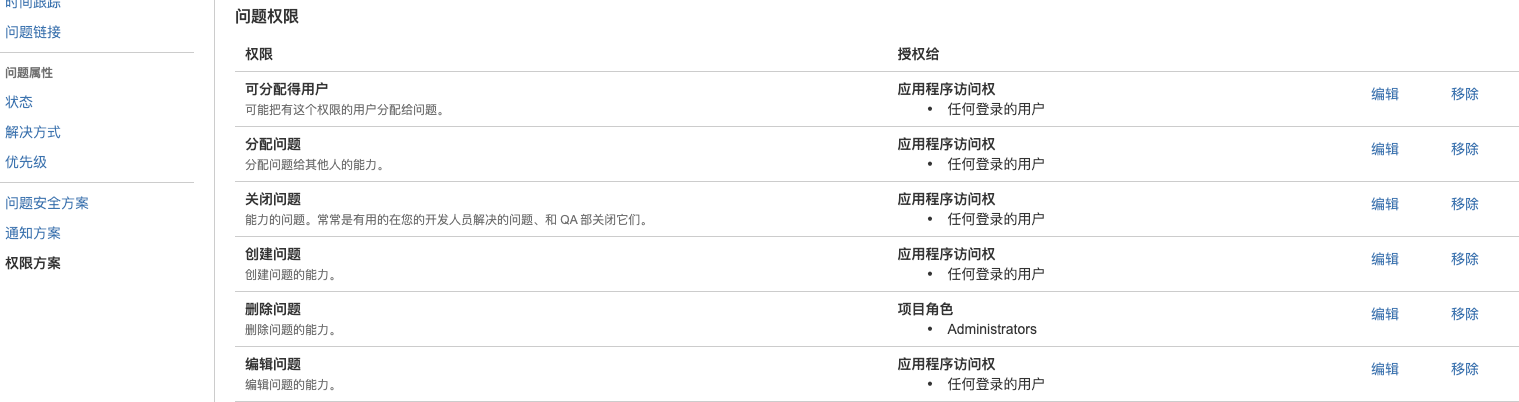
cdflow 工作流: 转换配置后处理功能:环境更改为 UAT 或 PRO 工作流条件限定组转换状态:DBA 组限定只能转换 SQL 状态等等
项目配置
- 问题类型:关联 升级 问题类型
- 工作流:切换工作流到自定义工作流 cdflow
- 域:关联到自定义字段方案
- 用户和作用:项目角色管理,暂不需要
- 权限:关联到自定义权限方案
- 通知:关联到自定义通知方案
用户管理
- 新增用户:略
- 新增组:通知组(用于 Jira 事件通知)、测试组、DBA 组
Reference: